Written: 10 Sep 2019 by Sebastian Ruder and Julian Eisenschlos
•
Classification
Most of the world’s text is not in English. To enable researchers and practitioners to build impactful solutions in
their domains, understanding how our NLP architectures fare in many languages needs to be more than an afterthought.
In this post, we introduce our latest paper that studies multilingual text classification and introduces MultiFiT,
a novel method based on ULMFiT.
MultiFiT, trained on 100 labeled documents in the target language, outperforms
multi-lingual BERT.
It also outperforms the cutting-edge LASER
algorithm—even though LASER requires a corpus of parallel texts, and MultiFiT does not.
This is joint work by Sebastian Ruder, Piotr Czapla, Marcin Kardas, Sylvain Gugger, Jeremy Howard, and Julian Eisenschlos
and benefits from the hundreds of insights
into multilingual transfer learning from the whole fast.ai forum community.
We invite you to read the full EMNLP 2019 paper
or check out the code here.
Introduction
If you have ever worked on an NLP task in any language other than English, we feel your pain. The last couple of
years have brought impressive progress in deep learning-based approaches for natural language processing tasks and
there’s much to be excited about. However, those advances can be slow to transfer beyond English. In the
past, most of academia showed little interest in publishing research or building datasets that go beyond the English language,
even though industry applications desperately need language-agnostic techniques. Luckily,
thanks to efforts around democratizing access to machine learning and initiatives such as the
Bender rule,
the tides are changing.
Existing approaches for cross-lingual NLP rely on either:
Parallel data across languages—that is, a corpus of documents with exactly the same contents, but written in different languages.
This is very hard to acquire in a general setting.
A shared vocabulary—that is, a vocabulary that is common across multiple languages. This approach over-represents languages with a lot of data.
For some examples, have a look at this blog post
An example is multilingual BERT,
which is very resource-intensive to train, and can struggle when languages are dissimilar.
The main appeal of cross-lingual models like multilingual BERT are their zero-shot transfer capabilities: given only
labels in a high-resource language such as English, they can transfer to another language without any training data in
that language. We argue that many low-resource applications do not provide easy access to training data in a
high-resource language. Such applications include disaster response on social media, help desks that deal with
community needs or support local business owners, etc. In such settings, it is often easier to collect a few hundred training
examples in the low-resource language. The utility of zero-shot approaches in general is quite limited;
by definition, if you are applying a model to some language, then you have some documents in that language.
So it makes sense to use them to help train your model!
In addition, when the target language is very different to the source language (most often English), zero-shot transfer
may perform poorly or fail altogether. We have seen this with cross-lingual word embeddings
and more recently for multilingual BERT.
We show that we can fine-tune efficient monolingual language models that are competitive with multilingual BERT,
in many languages, on a few hundred examples. Our proposed approach Multilingual Fine-Tuning (MultiFiT) is different
in a number of ways from the current main stream of NLP models: We do not build on BERT, but leverage a more efficient
variant of an LSTM architecture. Consequently, our approach is much cheaper to pretrain and more efficient in terms of
space and time complexity. Lastly, we emphasize having nimble monolingual models vs. a monolithic cross-lingual one.
We also show that we can achieve superior zero-shot transfer by using a cross-lingual model as the teacher.
This highlights the potential of combining monolingual and cross-lingual information.
Our approach
Our method is based on Universal Language Model Fine-Tuning (ULMFiT).
For more context, we invite you to check out the
previous blog post that explains it in depth.
MultiFiT extends ULMFiT to make it more efficient and more suitable for
language modelling beyond English: It utilizes tokenization based on subwords rather than words and employs a QRNN
rather than an LSTM. In addition, it leverages a number of other improvements.
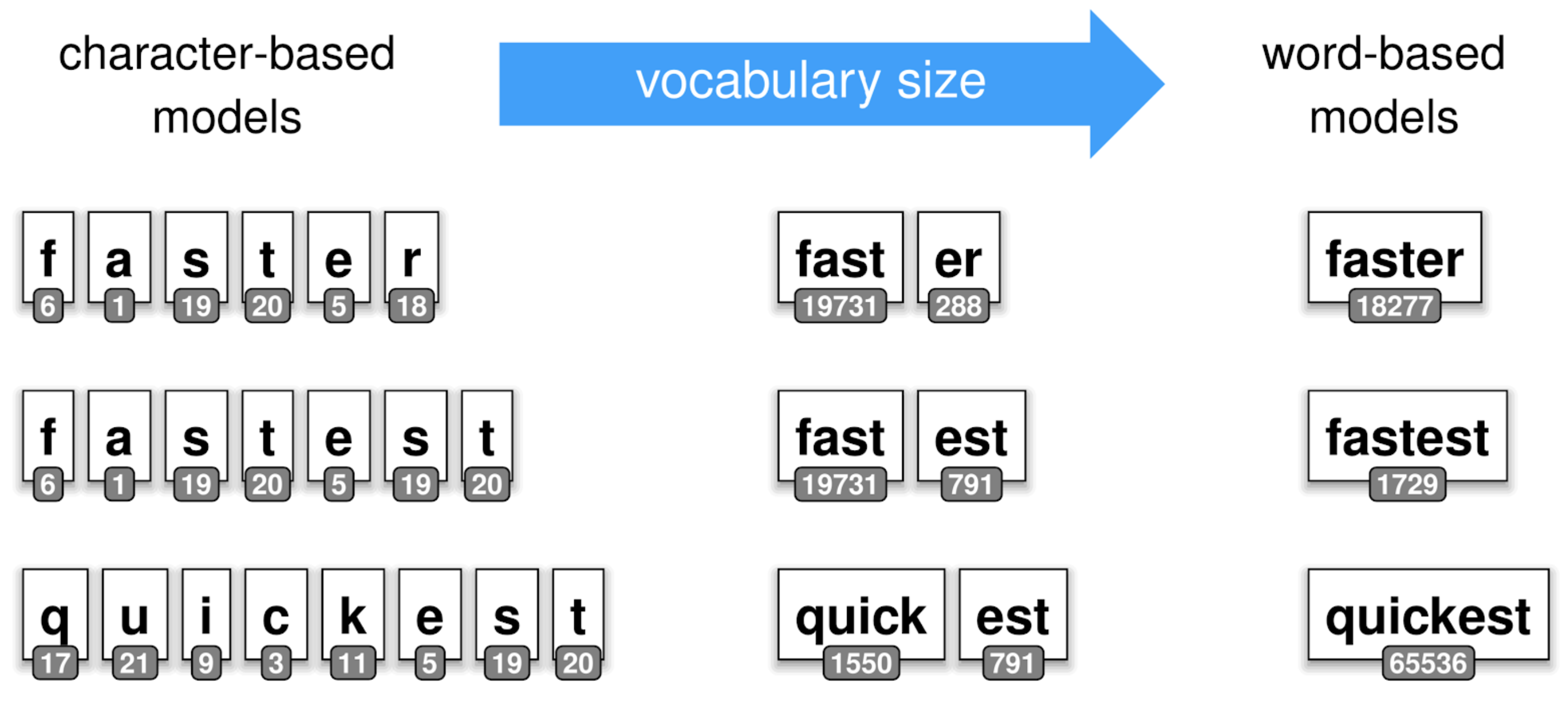
Subword tokenization ULMFiT uses word-based tokenization, which works well for the morphologically poor English,
but results in very large and sparse vocabularies for morphologically rich languages, such as Polish and Turkish.
Some languages such as Chinese don’t really even have the concept of a “word”, so require heuristic segmentation approaches,
which tend to be complicated, slow, and inaccurate.
On the other extreme as can be seen below,
character-based models use individual characters as tokens. While in this case the vocabulary
(and thus the number of parameters) can be small, such models require modelling longer dependencies and can thus
be harder to train and less expressive than word-based models.
From character-based to word-based tokenization.
To mitigate this, similar to current neural machine translation models and pretrained language models like BERT and
GPT-2, we employ SentencePiece subword tokenization,
which has since been incorporated into the fast.ai text package.
Subword tokenization strikes a balance between the two approaches by using a mixture of character, subword and word
tokens, depending on how common they are.
This way we can have short (on average) representations of sentences, yet are
still able to encode rare words. We use a unigram language model based on Wikipedia that learns a vocabulary of
tokens together with their probability of occurrence. It assumes that tokens occur independently (hence the unigram in the name).
During tokenization this method finds the most probable segmentation into tokens from the vocabulary.
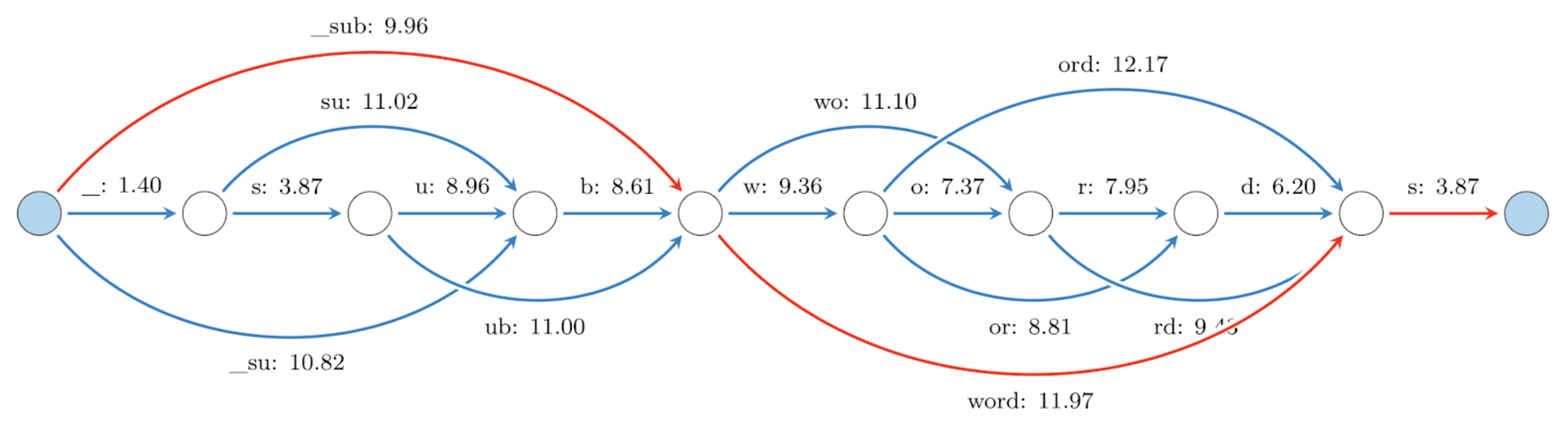
In the image below we show an example of tokenizing “_subwords” using a vocabulary trained on English Wikipedia
(“_” is used by SentencePiece to denote a whitespace).
A graph of possible subword tokenizations for the token '_subwords'. The number next to each token is its negative log
likelihood. The most probable tokenization corresponds to the shortest weighted path connecting the blue nodes
(indicated in red).
To sum up, subword tokenization has two very desirable properties for multilingual language modelling:
Subwords more easily represent inflections, including common prefixes and suffixes and are thus well-suited for
morphologically rich languages.
Subword tokenization is a good fit for open-vocabulary problems and eliminates out-of-vocabulary tokens, as the
coverage is close to 100% tokens.
QRNN ULMFiT used a state-of-the-art language model at the time, the AWD-LSTM.
The AWD-LSTM is a regular
LSTM with tuned dropout hyper-parameters. While recent state-of-the-art language models have been increasingly based on
Transformers, such as the Transformer-XL,
recurrent models still seem to have the edge on smaller datasets such as the Penn
Treebank and WikiText-2.
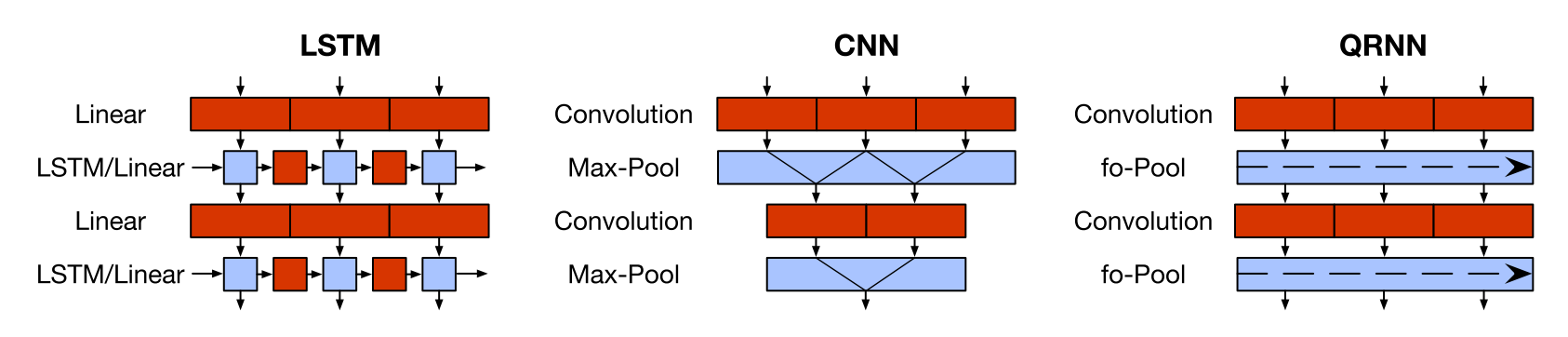
To make our model more efficient, we replace the AWD-LSTM with a Quasi-Recurrent Neural Network (QRNN).
The QRNN
strikes a balance between an CNN and an LSTM: It can be parallelized across time and minibatch dimensions like a CNN
and inherits the LSTM’s sequential bias as the output depends on the order of elements in the sequence.
Specifically, the QRNN alternates convolutional layers, which are parallel across timesteps and a recurrent pooling
function, which is parallel across channels.
We can see in the figure below how it differs from an LSTM and a CNN. In
the LSTM, computation at each timestep depends on the results from the previous timestep (indicated by the
non-continuous blocks), while CNNs and QRNNs are more easily parallelizable (indicated by the continuous blocks).
The computation structure of the QRNN compared with an LSTM and a CNN (Bradbury et al., 2019)
In our experiments, we obtain a 2-3x speed-up during training using QRNNs. QRNNs have been used in a number of
applications, such as state-of-the-art speech recognition in the past.
Other improvements Instead of using ULMFiT’s slanted triangular learning rate schedule and gradual
unfreezing, we achieve faster training and convergence by employing a cosine variant of the
one-cycle policy that is
available in the fast.ai library.
Finally, we use label smoothing,
which transforms the one-hot labels to a
“smoother” distribution and has been found particularly useful when learning from noisy labels.
ULMFiT ensembles the predictions of a forward and backward language model.
Even though bidirectionality has been found to be important
in contextual word vectors, we did not see big improvements for our downstream tasks (text classification)
with ELMo-style joint training. As joint training is quite memory-intensive
and we emphasize efficiency, we opted to just train forward language models for all languages.
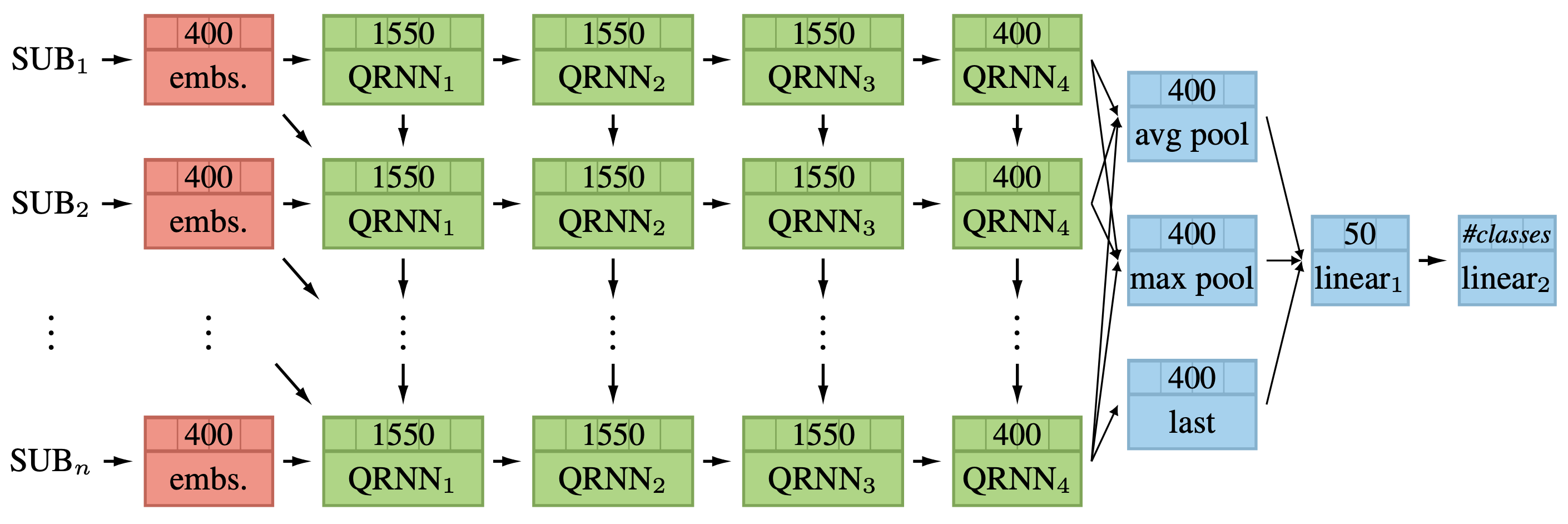
The full model can be seen in the below figure. It consists of a subword embedding layer,
four QRNN layers, an aggregation layer, and two linear layers. The aggregation and linear layers are the same as used in ULMFiT.
The MultiFiT language model with a classifier head.
The dimensionality of each layer can be seen in each box at the top (Figure 1 in the paper).
Results
We compare our model to state-of-the-art cross-lingual models including
multilingual BERT and LASER
(which uses parallel sentences)
on two multilingual document
classification datasets. Perhaps surprisingly, we find that our monolingual language models fine-tuned only on 100
labeled examples of the corresponding task in the target language outperform zero-shot inference (trained on 1000
examples in the source language) with multilingual BERT and LASER.
MultiFit also outperforms the other methods when all models are fine-tuned on 1000 target language examples.
For the detailed results, have a look at the paper.
Zero-shot Transfer with a Cross-lingual Teacher
Still, if a powerful cross-lingual model and labeled data in a high-resource language are available, it would be nice to
make use of them in some way. To this end, we propose to use the classifier that is learned on top of the cross-lingual
model on the source language data as a teacher to obtain labels for training our model on the target language.
This way, we can perform zero-shot transfer using our monolingual language model by bootstrapping from a
cross-lingual one.
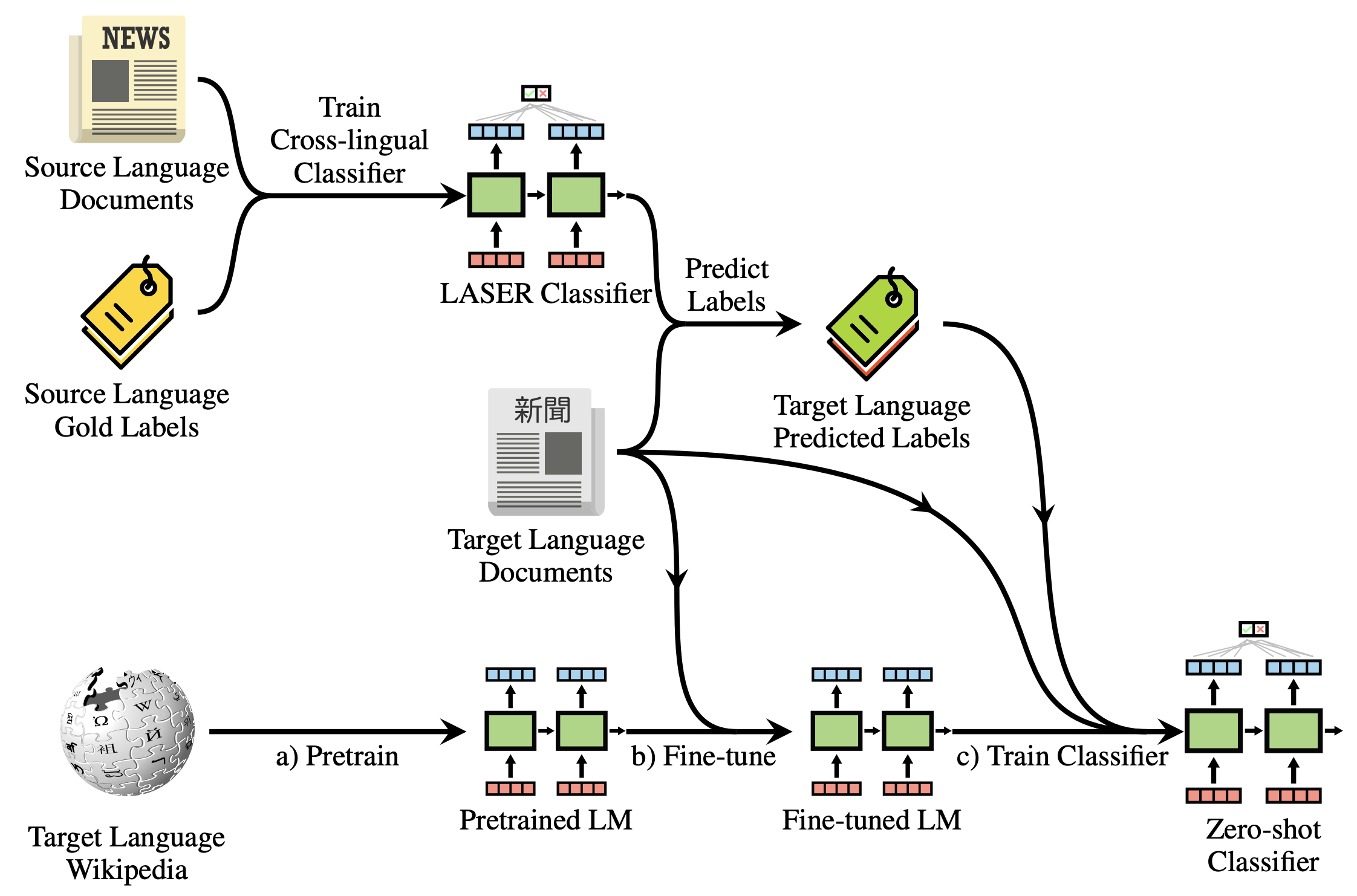
To illustrate how this works, take a look at the following diagram:
The steps of the cross-lingual bootstrapping method for zero-shot cross-lingual transfer (Figure 2 in
the paper).
The process consists of three main steps:
Our monolingual language model is pretrained on Wikipedia data in the target language (a) and fine-tuned on
in-domain data of the corresponding task (b).
We now train a classifier on top of cross-lingual model such as LASER using labelled data in a high-resource source
language and perform zero-shot inference as usual with this classifier to predict labels on target language documents.
In a the final step (c), we can now use these predicted labels to fine-tune a classifier on top of our fine-tuned
monolingual language model.
This is similar to distillation,
which has recently been used to train smallerlanguage models or distill
task-specific information into downstream models. In contrast, to previous work, we do not just seek to distill the
information of a big model into a small model but into one with a different inductive bias. In addition to
circumventing the need for labels in the target language, our approach thus brings another benefit: As the
monolingual model is specialized to the target language, its inductive bias might be more suitable than the more
language-agnostic representations learned by the cross-lingual model. It might thus be able to make
better use of labels in the target language, even if they are noisy.
We obtain evidence for this hypothesis as the monolingual language model fine-tuned on zero-shot predictions
outperforms its teacher in all settings.
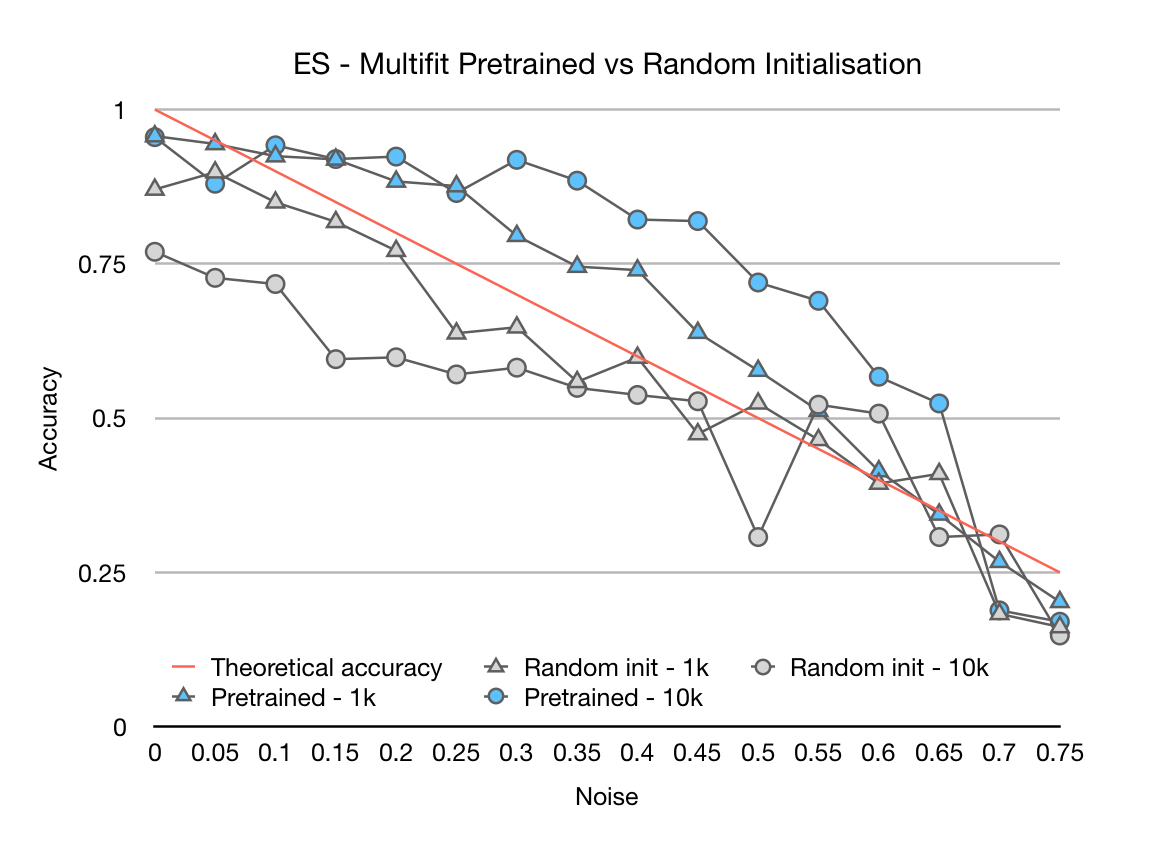
Robustness to Noise
Another hypothesis why this teaching works so well is that pretraining makes the monolingual language robust to
noise to some extent. The pretrained information stored in the model may act as a regularizer, biasing it towards
the correct labels that are in line with its knowledge of the language.
To test this, we compare a pretrained language model with a non-pretrained language model that are fine-tuned on
1k or 10k labelled examples where labels are perturbed with a probability ranging from 0 to 0.75 in the below diagram.
Comparison of MultiFiT's robustness to label noise with and without pretraining.
The red line shows the theoretical accuracy of a perfect model that achieves 100% accuracy with all labels.
As we can see, the pretrained models are much more robust to label noise. Even with 30% noisy labels, they still
maintain about the same performance, whereas the performance of the models without pretraining quickly decays.
This highlights robustness to noise as an additional benefit of transfer learning and may facilitate faster crowd-sourcing and data annotation.
Next Steps
We are initially releasing seven pre-trained language models in German, Spanish, French, Italian, Japanese, Russian, and
Chinese, since they are the ones in the datasets we studied. You can find the code here.
We hope to release many many more, with the help of the community.
Another interesting question to explore further is how very low-resource languages or dialects can benefit from larger
corpora in similar languages.
We are looking forward to seeing what problems you apply MultiFiT to,
so don’t hesitate to ask and share your results in the fast.ai forums.
Written: 15 May 2018 by Jeremy Howard and Sebastian Ruder
•
Classification
This post is a lay-person’s introduction to our new paper, which shows how to classify documents automatically with both higher accuracy and less data requirements than previous approaches. We’ll explain in simple terms: natural language processing; text classification; transfer learning; language modeling; and how our approach brings these ideas together. If you’re already familar with NLP and deep learning, you’ll probably want to jump over to our NLP classification page for technical links.
This method dramatically improves over previous approaches to text classification, and the code and pre-trained models allow anyone to leverage this new approach to better solve problems such as:
Finding documents relevant to a legal case;
Identifying spam, bots, and offensive comments;
Classifying positive and negative reviews of a product;
Grouping articles by political orientation;
…and much more.
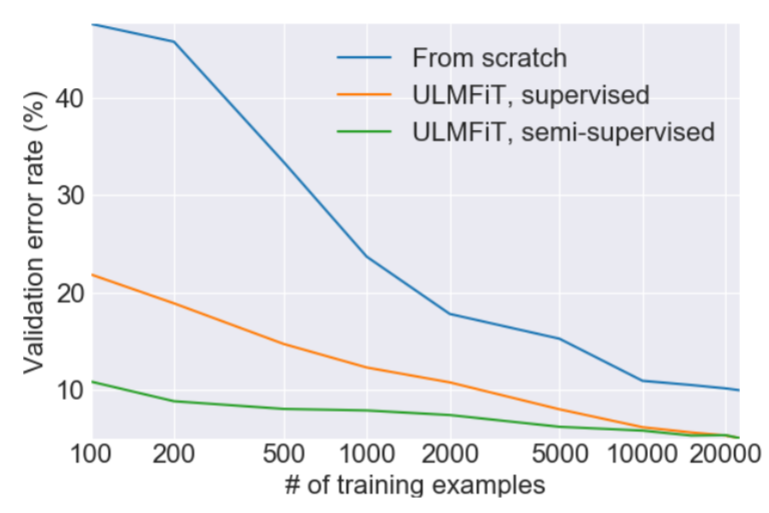
ULMFiT requires orders of magnitude less data than previous approaches. (Figure 3 from the paper)
So what does this new technique do exactly? Let’s first of all take a look at part of the abstract from the paper and see what it says—and then in the rest of this article we’ll unpack this and learn exactly what it all means:
Transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data.
NLP, deep learning, and classification
Natural language processing (NLP) is an area of computer science and artificial intelligence that deals with (as the name suggests) using computers to process natural language. Natural language refers to the normal languages we use to communicate day to day, such as English or Chinese—as opposed to specialized languages like computer code or music notation. NLP is used in a wide variety of applications, such as search, personal assistants, summarization, etc. Overall, NLP is challenging as the strict rules we use when writing computer code are a poor fit for the nuance and flexibility of language. You’ve likely run into those limitations yourself, with the frustrating experience of trying to communicate with automated phone answering systems, or limited capabilities of early “conversational bots” like Siri.
In the last couple of years we’ve started to see deep learning making significant inroads into areas where computers have previously seen limited success. Rather than requiring a set of fixed rules that are defined by the programmer, deep learning uses neural networks that learn rich non-linear relationships directly from data. Most notable is the success of deep learning in computer vision, as seen for example in the rapid progress in image classification in the Imagenet competition.
Deep learning has also seen some success in NLP, for example in automatic translation, as discussed in this extensive NY Times article. A common feature of successful NLP tasks is that large amounts of labeled data are available for training a model. However, until now such applications were limited to those institutions that were able to collect and label huge datasets and had the computational resources to process them on a cluster of computers for a long time.
One particulaar area that is still challenging with deep learning for NLP, curiously enough, is the exact area where it’s been most successful in computer vision: classification. This refers to any problem where your goal is to categorize things (such as images, or documents) into groups (such as images of cats vs dogs, or reviews that are positive vs negative, and so forth). A huge number of important real-world problems turn out to largely be about classification, which is why, for example, the success of deep learning on Imagenet (which is a classification problem) has led to a great many commercial applications. In NLP, current approaches are good at identifying, for instance, when a movie review is positive or negative, a problem known as sentiment analysis. Models struggle, however, as soon as things get more ambiguous, as often there is not enough labeled data to learn from.
Transfer learning
Our goal was to address these two problems: a) deal with NLP problems where we don’t have masses of data and computational resources, and b) make NLP classification easier. As it turned out, we (Jeremy and Sebastian) had both been working on the exact field that would solve this: transfer learning. Transfer learning refers to the use of a model that has been trained to solve one problem (such as classifying images from Imagenet) as the basis to solve some other somewhat similar problem. One common way to do this is by fine-tuning the original model (such as classifying CT scans into cancerous or not—an application of transfer learning that Jeremy developed when he founded Enlitic). Because the fine-tuned model doesn’t have to learn from scratch, it can generally reach higher accuracy with much less data and computation time than models that don’t use transfer learning.
Very simple transfer learning using just a single layer of weights (known as embeddings) has been extremely popular for some years, such as the word2vec embeddings from Google. However, full neural networks in practice contain many layers, so only using transfer learning for a single layer was clearly just scratching the surface of what’s possible.
The question, then, was what could we transfer from, in order to solve NLP problems? The answer to this question fell into Jeremy’s lap, when his friend Stephen Merity announced he had developed the AWD LSTM language model, which was a dramatic improvement over previous approaches to language modeling. A language model is an NLP model which learns to predict the next word in a sentence. For instance, if your mobile phone keyboard guesses what word you are going to want to type next, then it’s using a language model. The reason this is important is because for a language model to be really good at guessing what you’ll say next, it needs a lot of world knowledge (e.g. “I ate a hot” → “dog”, “It is very hot” → “weather”), and a deep understanding of grammar, semantics, and other elements of natural language. This is exactly the kind of knowledge that we leverage implicitly when we read and classify a document.
We found that in practice this approach to transfer learning has the features that allow it to be a universal approach to NLP transfer learning:
It works across tasks varying in document size, number, and label type
It uses a single architecture and training process
It requires no custom feature engineering or preprocessing
It does not require additional in-domain documents or labels.
Making it work
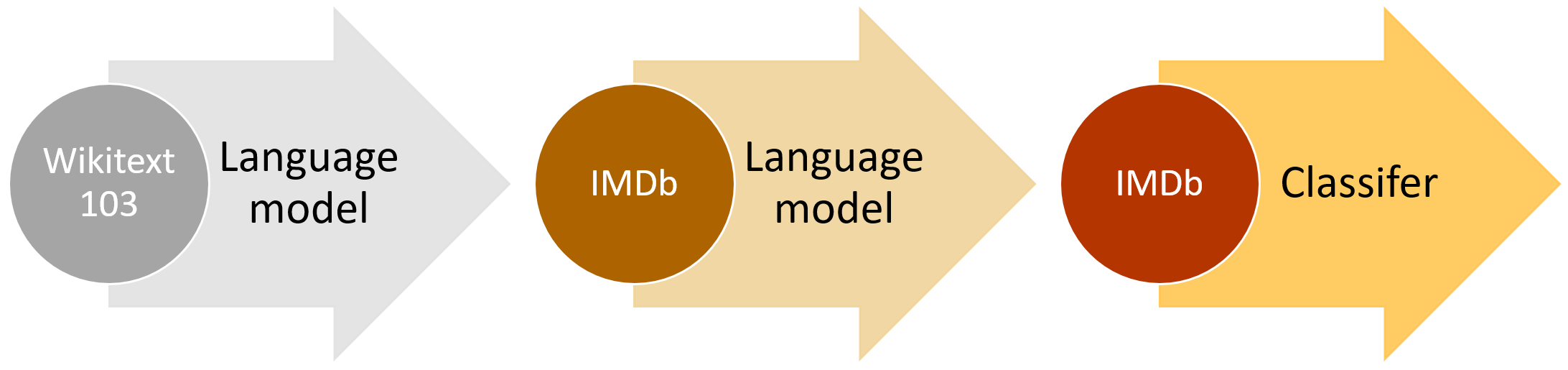
High level ULMFiT approach (IMDb example)
This idea has been tried before, but required millions of documents for adequate performance. We found that we could do a lot better by being smarter about how we fine-tune our language model. In particular, we found that if we carefully control how fast our model learns and update the pre-trained model so that it does not forget what it has previously learned, the model can adapt a lot better to a new dataset. One thing that we were particularly excited to find is that the model can learn well even from a limited number of examples. On one text classification dataset with two classes, we found that training our approach with only 100 labeled examples (and giving it access to about 50,000 unlabeled examples), we were able to achieve the same performance as training a model from scratch with 10,000 labeled examples.
Another important insight was that we could use any reasonably general and large language corpus to create a universal language model—something that we could fine-tune for any NLP target corpus. We decided to use Stephen Merity’s Wikitext 103 dataset, which contains a pre-processed large subset of English Wikipedia.
Research in NLP has mostly focused on English and training a model on a non-English language comes with its own set of challenges. Generally, the number of public datasets for non-English languages is small; if you want to train a text classification model for a language such as Thai, you invariably have to collect your own data. Collecting data in a non-English language often means that you need to annotate the data or find annotators yourself, as crowd-sourcing services such as Amazon Mechanical Turk mostly employ English-speaking annotators.
With ULMFiT, we can make training text classification models for languages other than English a lot easier as all we need is access to a Wikipedia, which is currently available for 301 languages, a small number of documents that can easily be annotated by hand, and optionally additional unlabeled documents. To make this even easier, we will soon launch a model zoo with pre-trained language models for many languages.
The future of ULMFiT
We have found that the approach works well on different tasks with the same settings. Besides text classification, there are many other important NLP problems, such as sequence tagging or natural language generation, that we hope ULMFiT will make easier to tackle in the future. We will be updating this site as we complete our experiments and build models in these areas.
In computer vision the success of transfer learning and availability of pre-trained Imagenet models has transformed the field. Many people including entrepreneurs, scientists, and engineers are now using fine-tuned Imagenet models to solve important problems involving computer vision—everything from improving crop yields in Africa to building robots that sort lego bricks. Now that the same tools are available for processing natural language, we hope to see the same explosion of applications in this field too.
Whilst we already have shown state of the art results for text classification, there’s still a lot of work to be done to really get the most out of NLP transfer learning. In the computer vision world there have been a number of important and insightful papers that have analyzed transfer learning in that field in depth. In particular, Yosinski et al. tried to answer the question “how transferable are features in deep neural networks”, and Huh et al. studied “what makes ImageNet good for transfer learning”. Yosinski even created a rich visualization toolkit to help practitioners better understand the features in their computer vision models (shown in the video below).
Deep Visualization Toolbox
If you try out ULMFiT on a new problem or dataset, we’d love to hear about it! Drop by the deep learning forums and tell us how it goes (and do let us know if you have any questions along the way).