Introduction
If you have ever worked on an NLP task in any language other than English, we feel your pain. The last couple of years have brought impressive progress in deep learning-based approaches for natural language processing tasks and there’s much to be excited about. However, those advances can be slow to transfer beyond English. In the past, most of academia showed little interest in publishing research or building datasets that go beyond the English language, even though industry applications desperately need language-agnostic techniques. Luckily, thanks to efforts around democratizing access to machine learning and initiatives such as the Bender rule, the tides are changing.
Existing approaches for cross-lingual NLP rely on either:
- Parallel data across languages—that is, a corpus of documents with exactly the same contents, but written in different languages. This is very hard to acquire in a general setting.
- A shared vocabulary—that is, a vocabulary that is common across multiple languages. This approach over-represents languages with a lot of data. For some examples, have a look at this blog post An example is multilingual BERT, which is very resource-intensive to train, and can struggle when languages are dissimilar.
The main appeal of cross-lingual models like multilingual BERT are their zero-shot transfer capabilities: given only labels in a high-resource language such as English, they can transfer to another language without any training data in that language. We argue that many low-resource applications do not provide easy access to training data in a high-resource language. Such applications include disaster response on social media, help desks that deal with community needs or support local business owners, etc. In such settings, it is often easier to collect a few hundred training examples in the low-resource language. The utility of zero-shot approaches in general is quite limited; by definition, if you are applying a model to some language, then you have some documents in that language. So it makes sense to use them to help train your model!
In addition, when the target language is very different to the source language (most often English), zero-shot transfer may perform poorly or fail altogether. We have seen this with cross-lingual word embeddings and more recently for multilingual BERT.
We show that we can fine-tune efficient monolingual language models that are competitive with multilingual BERT, in many languages, on a few hundred examples. Our proposed approach Multilingual Fine-Tuning (MultiFiT) is different in a number of ways from the current main stream of NLP models: We do not build on BERT, but leverage a more efficient variant of an LSTM architecture. Consequently, our approach is much cheaper to pretrain and more efficient in terms of space and time complexity. Lastly, we emphasize having nimble monolingual models vs. a monolithic cross-lingual one. We also show that we can achieve superior zero-shot transfer by using a cross-lingual model as the teacher. This highlights the potential of combining monolingual and cross-lingual information.
Our approach
Our method is based on Universal Language Model Fine-Tuning (ULMFiT). For more context, we invite you to check out the previous blog post that explains it in depth. MultiFiT extends ULMFiT to make it more efficient and more suitable for language modelling beyond English: It utilizes tokenization based on subwords rather than words and employs a QRNN rather than an LSTM. In addition, it leverages a number of other improvements.
Subword tokenization ULMFiT uses word-based tokenization, which works well for the morphologically poor English, but results in very large and sparse vocabularies for morphologically rich languages, such as Polish and Turkish. Some languages such as Chinese don’t really even have the concept of a “word”, so require heuristic segmentation approaches, which tend to be complicated, slow, and inaccurate. On the other extreme as can be seen below, character-based models use individual characters as tokens. While in this case the vocabulary (and thus the number of parameters) can be small, such models require modelling longer dependencies and can thus be harder to train and less expressive than word-based models.
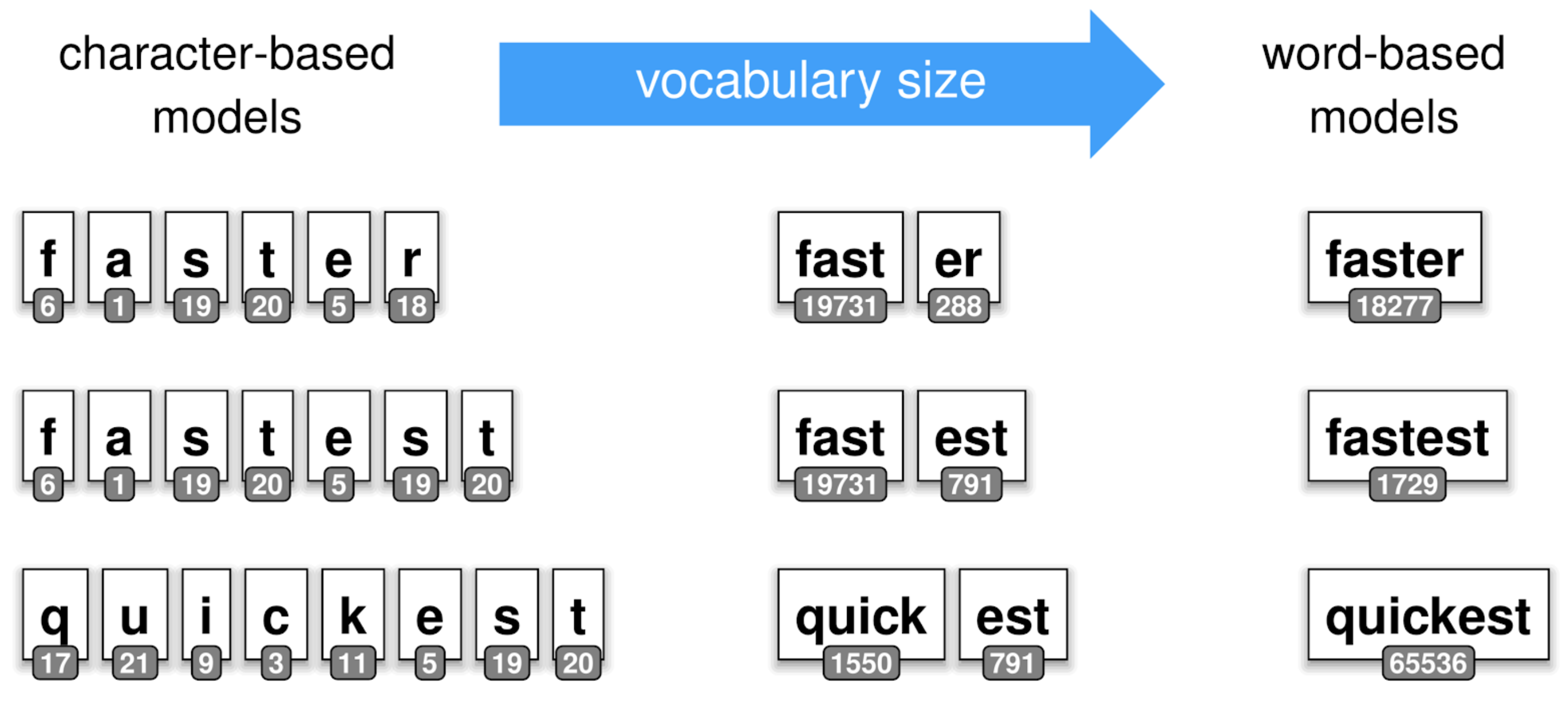
To mitigate this, similar to current neural machine translation models and pretrained language models like BERT and GPT-2, we employ SentencePiece subword tokenization, which has since been incorporated into the fast.ai text package. Subword tokenization strikes a balance between the two approaches by using a mixture of character, subword and word tokens, depending on how common they are.
This way we can have short (on average) representations of sentences, yet are still able to encode rare words. We use a unigram language model based on Wikipedia that learns a vocabulary of tokens together with their probability of occurrence. It assumes that tokens occur independently (hence the unigram in the name). During tokenization this method finds the most probable segmentation into tokens from the vocabulary. In the image below we show an example of tokenizing “_subwords” using a vocabulary trained on English Wikipedia (“_” is used by SentencePiece to denote a whitespace).
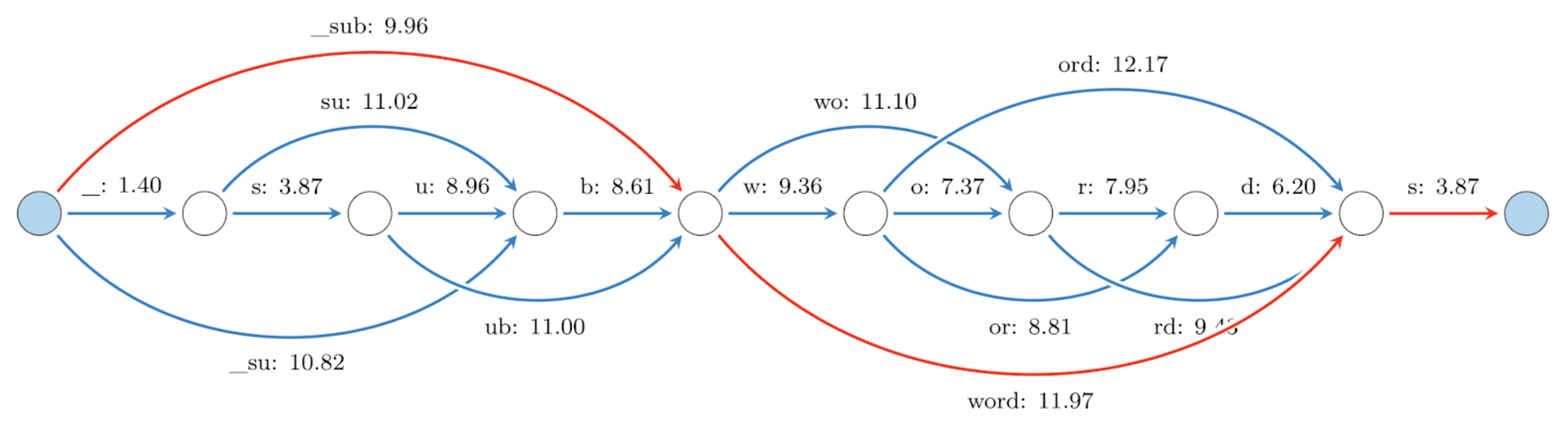
To sum up, subword tokenization has two very desirable properties for multilingual language modelling:
- Subwords more easily represent inflections, including common prefixes and suffixes and are thus well-suited for morphologically rich languages.
- Subword tokenization is a good fit for open-vocabulary problems and eliminates out-of-vocabulary tokens, as the coverage is close to 100% tokens.
QRNN ULMFiT used a state-of-the-art language model at the time, the AWD-LSTM. The AWD-LSTM is a regular LSTM with tuned dropout hyper-parameters. While recent state-of-the-art language models have been increasingly based on Transformers, such as the Transformer-XL, recurrent models still seem to have the edge on smaller datasets such as the Penn Treebank and WikiText-2.
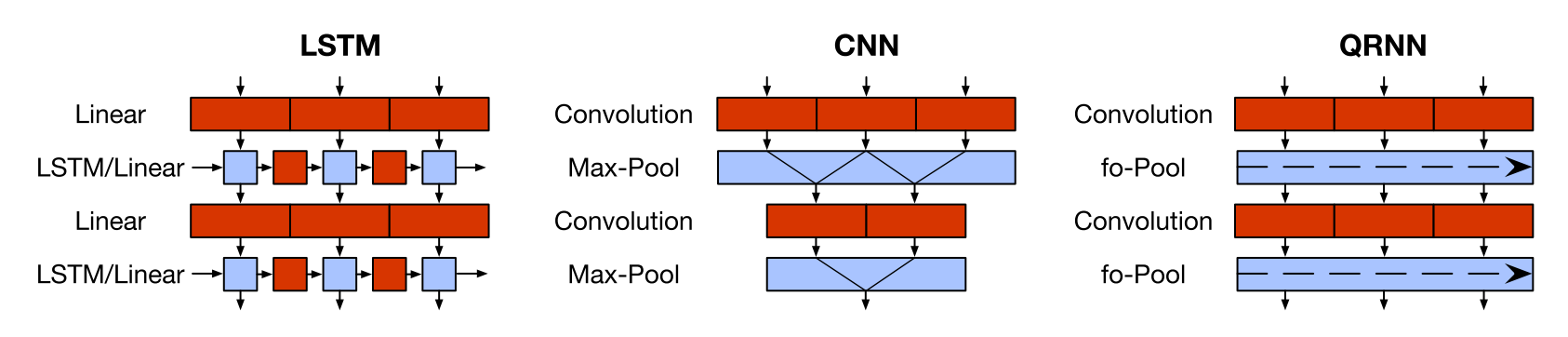
To make our model more efficient, we replace the AWD-LSTM with a Quasi-Recurrent Neural Network (QRNN). The QRNN strikes a balance between an CNN and an LSTM: It can be parallelized across time and minibatch dimensions like a CNN and inherits the LSTM’s sequential bias as the output depends on the order of elements in the sequence. Specifically, the QRNN alternates convolutional layers, which are parallel across timesteps and a recurrent pooling function, which is parallel across channels.
We can see in the figure below how it differs from an LSTM and a CNN. In the LSTM, computation at each timestep depends on the results from the previous timestep (indicated by the non-continuous blocks), while CNNs and QRNNs are more easily parallelizable (indicated by the continuous blocks).
In our experiments, we obtain a 2-3x speed-up during training using QRNNs. QRNNs have been used in a number of applications, such as state-of-the-art speech recognition in the past.
Other improvements Instead of using ULMFiT’s slanted triangular learning rate schedule and gradual unfreezing, we achieve faster training and convergence by employing a cosine variant of the one-cycle policy that is available in the fast.ai library. Finally, we use label smoothing, which transforms the one-hot labels to a “smoother” distribution and has been found particularly useful when learning from noisy labels.
ULMFiT ensembles the predictions of a forward and backward language model. Even though bidirectionality has been found to be important in contextual word vectors, we did not see big improvements for our downstream tasks (text classification) with ELMo-style joint training. As joint training is quite memory-intensive and we emphasize efficiency, we opted to just train forward language models for all languages.
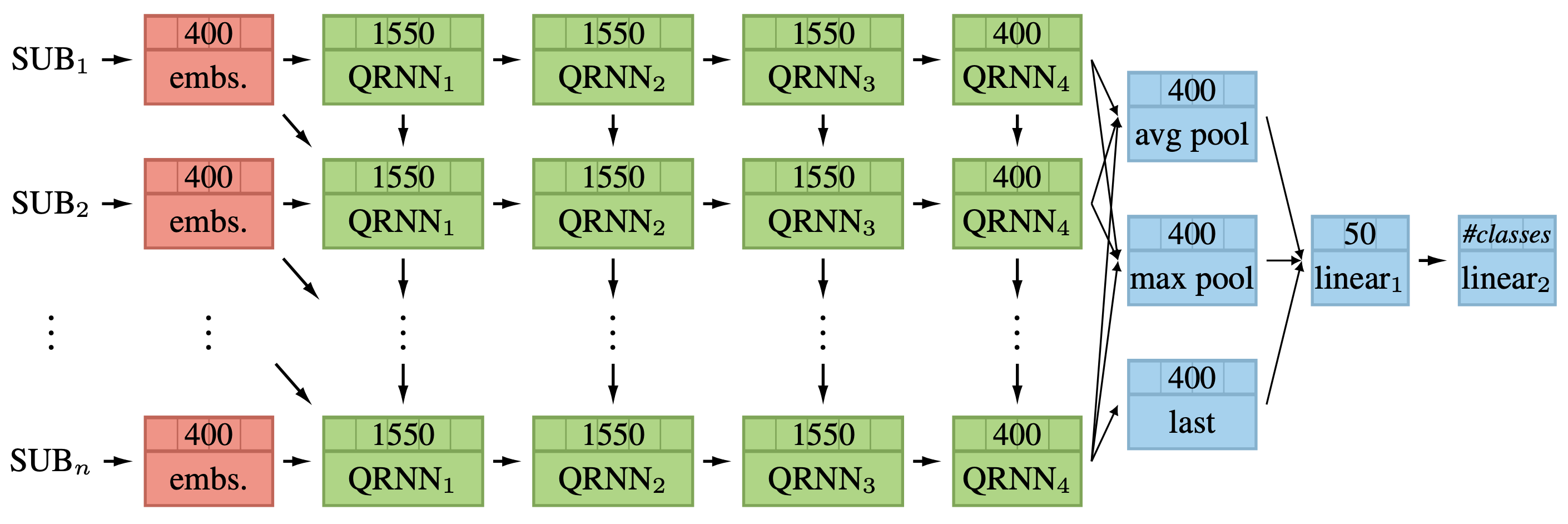
The full model can be seen in the below figure. It consists of a subword embedding layer, four QRNN layers, an aggregation layer, and two linear layers. The aggregation and linear layers are the same as used in ULMFiT.
Results
We compare our model to state-of-the-art cross-lingual models including multilingual BERT and LASER (which uses parallel sentences) on two multilingual document classification datasets. Perhaps surprisingly, we find that our monolingual language models fine-tuned only on 100 labeled examples of the corresponding task in the target language outperform zero-shot inference (trained on 1000 examples in the source language) with multilingual BERT and LASER. MultiFit also outperforms the other methods when all models are fine-tuned on 1000 target language examples.
For the detailed results, have a look at the paper.
Zero-shot Transfer with a Cross-lingual Teacher
Still, if a powerful cross-lingual model and labeled data in a high-resource language are available, it would be nice to make use of them in some way. To this end, we propose to use the classifier that is learned on top of the cross-lingual model on the source language data as a teacher to obtain labels for training our model on the target language. This way, we can perform zero-shot transfer using our monolingual language model by bootstrapping from a cross-lingual one.
To illustrate how this works, take a look at the following diagram:
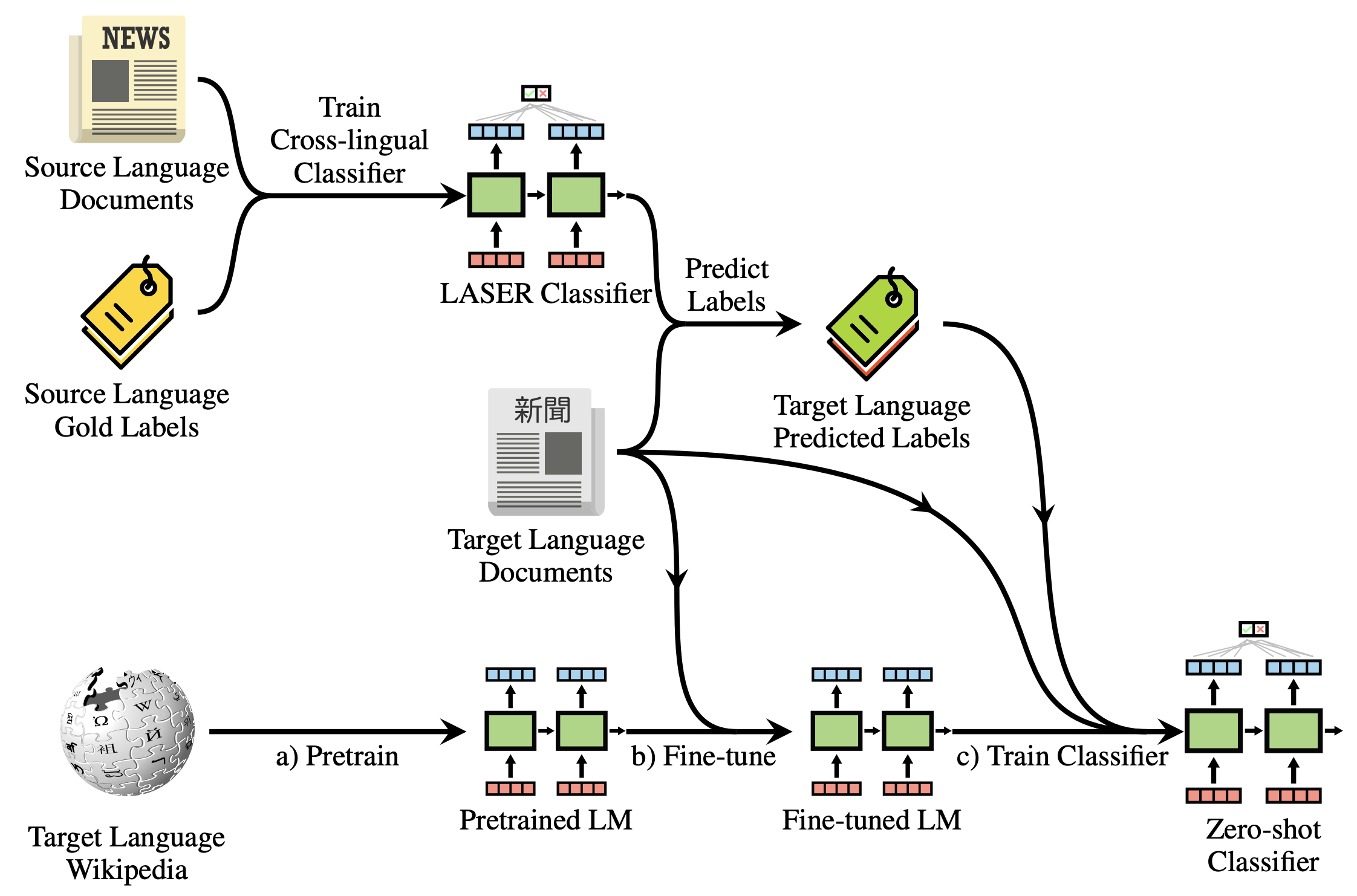
The process consists of three main steps:
- Our monolingual language model is pretrained on Wikipedia data in the target language (a) and fine-tuned on in-domain data of the corresponding task (b).
- We now train a classifier on top of cross-lingual model such as LASER using labelled data in a high-resource source language and perform zero-shot inference as usual with this classifier to predict labels on target language documents.
- In a the final step (c), we can now use these predicted labels to fine-tune a classifier on top of our fine-tuned monolingual language model.
This is similar to distillation, which has recently been used to train smaller language models or distill task-specific information into downstream models. In contrast, to previous work, we do not just seek to distill the information of a big model into a small model but into one with a different inductive bias. In addition to circumventing the need for labels in the target language, our approach thus brings another benefit: As the monolingual model is specialized to the target language, its inductive bias might be more suitable than the more language-agnostic representations learned by the cross-lingual model. It might thus be able to make better use of labels in the target language, even if they are noisy.
We obtain evidence for this hypothesis as the monolingual language model fine-tuned on zero-shot predictions outperforms its teacher in all settings.
Robustness to Noise
Another hypothesis why this teaching works so well is that pretraining makes the monolingual language robust to noise to some extent. The pretrained information stored in the model may act as a regularizer, biasing it towards the correct labels that are in line with its knowledge of the language.
To test this, we compare a pretrained language model with a non-pretrained language model that are fine-tuned on 1k or 10k labelled examples where labels are perturbed with a probability ranging from 0 to 0.75 in the below diagram.
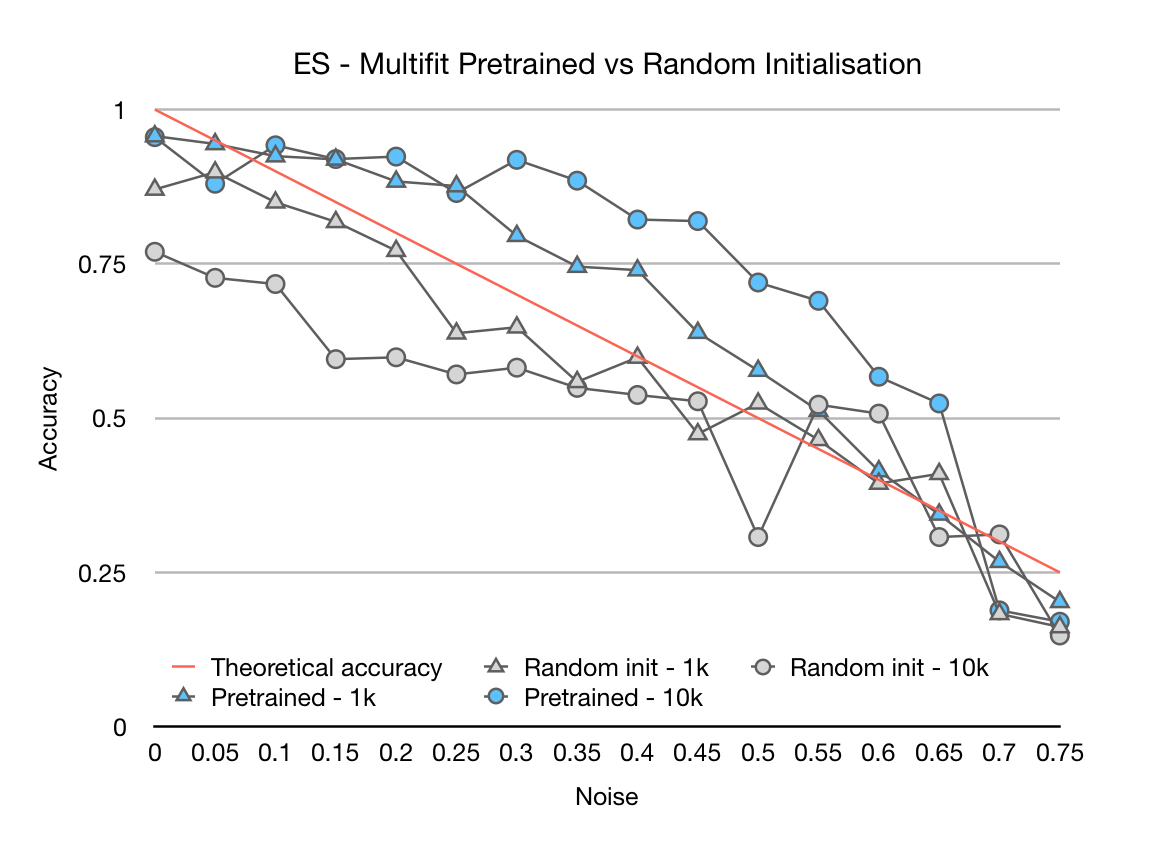
As we can see, the pretrained models are much more robust to label noise. Even with 30% noisy labels, they still maintain about the same performance, whereas the performance of the models without pretraining quickly decays. This highlights robustness to noise as an additional benefit of transfer learning and may facilitate faster crowd-sourcing and data annotation.
Next Steps
We are initially releasing seven pre-trained language models in German, Spanish, French, Italian, Japanese, Russian, and Chinese, since they are the ones in the datasets we studied. You can find the code here. We hope to release many many more, with the help of the community.
The fast.ai community has been very helpful in collecting datasets in many more languages, and applying MultiFiT to them—nearly always with state-of-the-art results. For space limitations in the paper those datasets were not included, and we opted to select well used, balanced multi-lingual datasets. Special thanks to Aayush Yadav, Alexey Demyanchuk, Benjamin van der Burgh, Cahya Wirawan, Charin Polpanumas, Nirant Kasliwal and Tomasz Pietruszka.
Another interesting question to explore further is how very low-resource languages or dialects can benefit from larger corpora in similar languages. We are looking forward to seeing what problems you apply MultiFiT to, so don’t hesitate to ask and share your results in the fast.ai forums.